










Modelos multimodais de grande porte (LMMs) integram múltiplos tipos de dados em um único modelo. Ao combinar dados de texto com imagens e outras modalidades durante o treinamento, modelos multimodais como Claude3, GPT-4V e Gemini Pro Vision ganham uma compreensão mais abrangente e uma capacidade aprimorada de processar diversos tipos de dados.
A abordagem multimodal permite que os modelos lidem com uma gama mais ampla de tarefas do mundo real que envolvem tanto entradas de texto quanto de não texto. Dessa forma, a multimodalidade ajuda a superar as restrições dos modelos de texto puro.
Os LMMs têm o potencial de impactar profundamente várias indústrias, como saúde, análise de negócios, direção autônoma e assim por diante. Um modelo de linguagem de uso geral, no entanto, pode processar apenas tarefas visuais relativamente simples, como responder a perguntas básicas sobre uma imagem ou gerar legendas curtas.
Isso se deve principalmente à falta de acesso a informações detalhadas em nível de pixel, dados de segmentação de objetos e outras anotações granulares que permitiriam que o modelo entendesse e raciocinasse com precisão sobre os vários elementos, relacionamentos e contexto dentro de uma imagem.
Sem essa compreensão visual detalhada, o modelo de linguagem fica limitado a capacidades de análise e geração mais superficiais e de alto nível relacionadas às imagens.
O ajuste fino dos LMMs em dados específicos do domínio pode melhorar significativamente seu desempenho em tarefas específicas.
A perspectiva de ajustar modelos multimodais de fonte aberta, como o LLaVA, é altamente atraente devido à sua eficácia em termos de custos, escalabilidade e desempenho impressionante em benchmarks multimodais.
Para aqueles que buscam soluções flexíveis e econômicas, a capacidade de usar e personalizar esses poderosos modelos tem um imenso potencial.
Neste artigo, demonstramos como ajustar e implantar o modelo LLaVA no Amazon SageMaker. O código-fonte está disponível neste repositório do GitHub.
Visão geral do LLaVA
O LLaVA é treinado de ponta a ponta para permitir a compreensão de uso geral em dados visuais e textuais. Na arquitetura do modelo LLaVA, modelos de linguagem pré-treinados, como o Vicuna ou o LLaMA, são combinados com modelos visuais, como o codificador visual do CLIP.
A integração converte as características visuais das imagens em um formato que corresponde aos embeddings do modelo de linguagem por meio de uma camada de projeção.
O treinamento do LLaVA acontece em duas etapas, conforme mostrado na Figura 1 um pouco mais abaixo.
A primeira etapa é o pré-treinamento, que usa pares de imagem-texto para alinhar as características visuais com os embeddings do modelo de linguagem. Nesta etapa, os pesos do codificador visual e do modelo de linguagem são mantidos congelados, e apenas a matriz de projeção é treinada.
A segunda etapa é o ajuste fino de todo o modelo de ponta a ponta. Aqui, os pesos do codificador visual são congelados, enquanto a camada de projeção e o modelo de linguagem são atualizados.
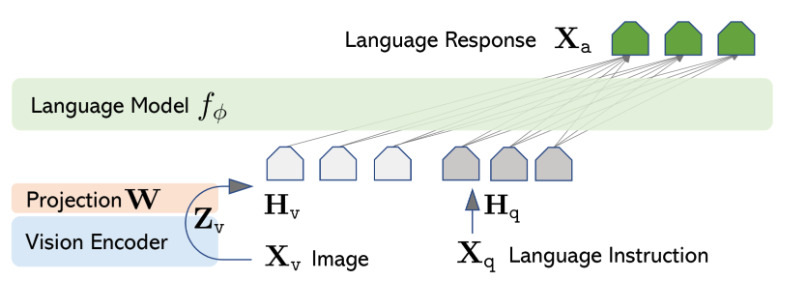
Figura 1: Arquitetura LLaVA
Preparação de dados
Quando se trata de ajustar o modelo LLaVA para tarefas ou domínios específicos, a preparação de dados é de importância primordial. Ter anotações de alta qualidade e abrangentes permite que o modelo aprenda representações ricas e alcance desempenho de nível humano em desafios complexos de raciocínio visual.
Neste blog post, nós nos concentramos na preparação de um conjunto de instruções.
Anotação de dados
O conjunto de dados deve conter pares de texto de imagem que envolvam raciocínio para responder a perguntas sobre as imagens. Para ajudar o modelo a ganhar compreensão abrangente durante o processo de treinamento, os dados de texto devem ser enriquecidos com nuances contextuais.
Por exemplo, em vez de simplesmente pedir ao modelo que descreva a imagem, faça perguntas específicas sobre a imagem e relacionadas ao seu conteúdo.
Para demonstrar as capacidades do LLaVA, criamos um pequeno conjunto de dados sintéticos focado na compreensão e interpretação de infográficos e gráficos. Usamos o Amazon Bedrock e o Python para esta tarefa.
Especificamente, empregamos o modelo Amazon Bedrock LLaMA2-70B para gerar descrições de texto e pares de perguntas e respostas com base nessas descrições. Posteriormente, usamos o Python para gerar diferentes tipos de apresentação visual, como gráficos de pizza e gráficos de funil, com base nas descrições de texto.
Se você já tiver um conjunto de dados existente, esse método pode ser usado como uma técnica de ampliação de dados para expandi-lo e, potencialmente, melhorar o resultado do ajuste fino.
Ao criar exemplos sintéticos de descrições de texto, pares de perguntas e respostas e gráficos correspondentes, você pode aumentar seu conjunto de dados com exemplos multimodais adaptados ao seu caso de uso específico.
O conjunto de dados que criamos consiste em pares de imagem-texto, sendo cada imagem um infográfico, gráfico ou outra visualização de dados.
O texto correspondente é uma série de perguntas sobre o infográfico, juntamente com respostas verdadeiras, formatadas em um estilo de pergunta-resposta destinado a se assemelhar ao modo como um humano poderia perguntar ao modelo sobre as informações contidas na imagem.
Alguns exemplos de perguntas geradas para as imagens mostradas na Figura 2 incluem:
- Qual é a porcentagem de pessoas que passam menos de 2 horas por dia em telas
- Qual a proporção de pessoas que não fazem exercícios semanalmente?
- Quantas pessoas são professores?
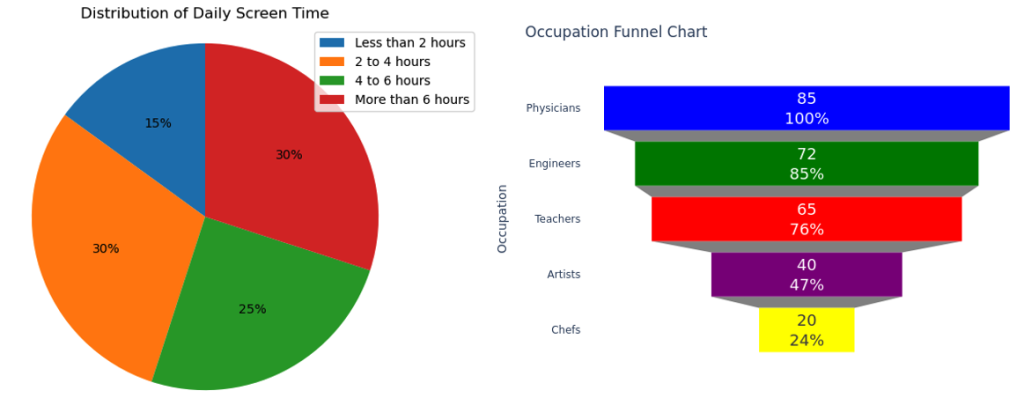
Figura 2: Exemplos de gráficos no conjunto de dados de treinamento (à esquerda um gráfico de pizza da distribuição do tempo diário de tela, à direita um gráfico de funil de ocupação).
Estrutura dos dados
Esses pares de imagem e texto devem ser formatados em JSON lines (formato .jsonl), em que cada linha é uma amostra de treinamento. Um exemplo de amostra de treinamento está ilustrado mais abaixo.
Especificamente, o campo id é o identificador exclusivo de uma amostra de treinamento, o campo image especifica o nome da imagem e o campo conversations fornece um par de pergunta e resposta.
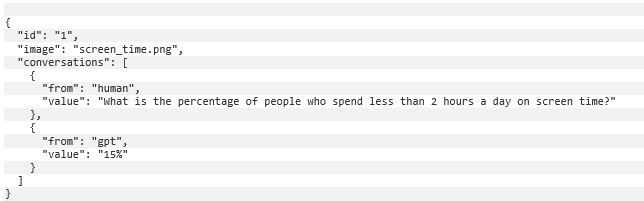
Ao treinar o modelo para responder a perguntas aprofundadas e analíticas sobre infográficos que nunca viu antes, pretendemos fortalecer a capacidade do modelo de generalizar sua compreensão de visualizações de dados e obter insights precisos.
Ajuste fino do modelo
Após os dados serem preparados, os enviamos para o Amazon Simple Storage Service (Amazon S3) como entrada de treinamento do SageMaker.
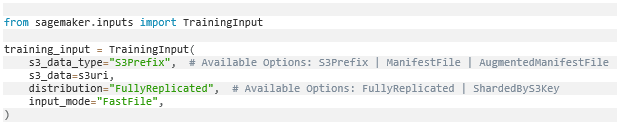
Ao configurar o trabalho de treinamento do SageMaker, usamos o objeto TrainingInput para especificar o local dos dados de entrada no Amazon S3 e definir como o SageMaker deve lidar com eles durante o treinamento.
Neste caso, input_mode=’FastFile’ indica o uso do modo de arquivo rápido do S3, que é ideal para cenários onde o conjunto de dados é armazenado como arquivos individuais no S3.
O modo de arquivo rápido do S3 também é vantajoso ao trabalhar com grandes conjuntos de dados ou quando o acesso rápido aos dados é fundamental para o desempenho do treinamento.
Vamos reutilizar o script de treinamento do LLaVA, que usa o DeepSpeed para eficiência de treinamento. O DeepSpeed é uma biblioteca que ajuda a treinar modelos de aprendizado profundo muito grandes de forma mais rápida e eficiente.
O ZeRO, sigla para Zero Redundancy Optimizer, é uma técnica de otimização de memória no DeepSpeed que reduz o consumo de memória necessário para o paralelismo de dados, particionando estados de otimização e gradientes entre processos paralelos de dados, permitindo tamanhos de modelo e lotes maiores dentro da memória GPU limitada. Isso permite que você treine modelos muito maiores no mesmo hardware.
O Estágio 2 do ZeRO reduz o uso de memória dividindo o estado do otimizador, os gradientes e os parâmetros do modelo em vários processos. Cada processo armazena apenas uma parte desses, reduzindo a memória necessária por processo. Se você encontrar erros de memória CUDA com essa configuração, tente a configuração do Estágio 3.
O Estágio 3 descarrega os gradientes para a CPU, o que diminui a velocidade de treinamento, mas pode resolver o problema de memória. O comando de treinamento é o seguinte.

O LLaVA permite que você ajuste todos os parâmetros do modelo base ou use o LoRA para ajustar um número menor de parâmetros.
A estratégia do LoRA mantém o backbone do modelo pré-treinado original inalterado e adiciona novas camadas mais fáceis de treinar. Isso permite uma adaptação rápida a novas tarefas sem retreiná-la completamente. Você pode usar o parâmetro lora_enable para especificar o método de ajuste fino.
Para ajuste fino de todos os parâmetros, recomenda-se o ml.p4d.24xlarge, enquanto o ml.g5.12xlarge é suficiente para o ajuste fino do LoRA, se for usado o modelo de linguagem LLaMA-13B.
O código a seguir inicializa um estimador SageMaker usando o SDK do HuggingFace. Ele configura um trabalho de treinamento SageMaker para executar o script de treinamento personalizado do LLaVA.
Isso permite que o script seja executado no ambiente gerenciado pelo SageMaker, aproveitando sua escalabilidade. Em seguida, nós trazemos nosso próprio contêiner Docker para executar o trabalho de treinamento do SageMaker.
Você pode baixar a imagem Docker deste repositório de código, onde as dependências do modelo de treinamento LLaVA estão instaladas. Para saber mais sobre como adaptar seu próprio contêiner Docker para funcionar com o SageMaker, consulte a adaptação do seu próprio contêiner de treinamento.
Para fins de registro, você pode usar definições de métricas para extrair métricas-chave dos logs impressos no script de treinamento e enviá-las para o Amazon CloudWatch.
A seguir, um exemplo de definição de métrica que registra a perda de treinamento em cada época, a taxa de aprendizagem do modelo e o throughput de treinamento.

Implantar e testar
Após a conclusão do trabalho de treinamento, o modelo ajustado é carregado no Amazon S3. Você pode então usar o código a seguir para implantar o modelo no SageMaker.
Para testar, forneça um par de imagem e pergunta e faça uma chamada de inferência no endpoint do SageMaker da seguinte forma:

Conclusão
Nossa exploração sobre o ajuste fino do modelo de linguagem visual LLaVA no Sagemaker para uma tarefa personalizada de perguntas e respostas sobre imagens lançou luz sobre os avanços realizados na ponte entre a compreensão textual e visual.
O LLaVA representa um passo significativo no avanço da IA multimodal, demonstrando a capacidade de compreender e raciocinar conjuntamente sobre informações textuais e visuais em um modelo unificado.
Ao usar o pré-treinamento em larga escala em pares de imagem-texto, o LLaVA adquiriu representações visiolinguísticas robustas que podem ser efetivamente adaptadas a tarefas downstream por meio do ajuste fino. Isso permite que o LLaVA se destaque em tarefas que exigem uma compreensão profunda de ambas as modalidades, como perguntas e respostas sobre imagens, legenda de imagens e recuperação de informações multimodais.
No entanto, o mecanismo de ajuste fino tem limitações. Em particular, o ajuste da camada de projeção e do modelo de linguagem em si, enquanto o modelo de visão é congelado, apresenta um conjunto de desafios, como a necessidade de uma quantidade massiva de dados e a falta de capacidade de lidar com tarefas de visão desafiadoras.
Enfrentar esses desafios diretamente nos permite desbloquear todo o potencial dos modelos multimodais, abrindo caminho para aplicações mais sofisticadas.
Amazon SageMaker, soluções de GenAI e LLMs de alto nível com a DNX Brasil e a AWS
Estamos sempre focados em garantir soluções que superem as expectativas dos nossos clientes. Nossa equipe de especialistas em IA e IA generativa tem ampla experiência no desenvolvimento de arquiteturas personalizadas para que sua empresa esteja preparada para oferecer o futuro dos softwares.
Nos links a seguir, você pode conferir Cases de Sucesso da DNX Brasil, Premier Partner Amazon Web Service, criados utilizando o Amazon SageMaker grandes modelos de linguagem (LLMs).
Alfaneo: Automatização da Geração de Petições Legais usando GenAI
IndeCX: Insights valiosos de Customer Experience através de IA Generativa
Unxpose: Revolucionando processos no setor de segurança da informação com GenAI
Artigo adaptado e traduzido do blog da AWS.
Artigos relacionados

29
abr

18
jul





01
jul


27
jun

19
jun


07
jun
