











No mundo do varejo online, criar descrições de alta qualidade para milhões de produtos é uma tarefa crucial, mas demorada.
Utilizar aprendizado de máquina (ML) e processamento de linguagem natural (NLP) para automatizar a geração de descrições de produtos tem o potencial de economizar esforço manual e transformar a forma como as plataformas de comércio eletrônico operam.
Uma das principais vantagens de descrições de produtos de alta qualidade é a melhoria na capacidade de busca. Os clientes podem localizar mais facilmente produtos que possuem descrições corretas, pois isso permite que o mecanismo de busca identifique produtos que correspondam não apenas à categoria geral, mas também aos atributos específicos mencionados na descrição do produto.
Por exemplo, um produto que tenha uma descrição que inclua palavras como “manga longa” e “gola de algodão” será exibido se um consumidor estiver procurando por uma “camisa de algodão de manga longa”.
Além disso, ter descrições de produtos detalhadas pode aumentar a satisfação do cliente, permitindo uma experiência de compra mais personalizada e melhorando os algoritmos para recomendar produtos mais relevantes aos usuários, o que aumenta a probabilidade de os usuários realizarem uma compra.
Com o avanço da IA Generativa, podemos usar modelos de linguagem-visão (VLMs) para prever atributos de produtos diretamente a partir de imagens
Modelos de legenda de imagens pré-treinados ou de resposta visual a perguntas (VQA) têm um bom desempenho na descrição de imagens do dia a dia, mas não conseguem captar as nuances específicas do domínio de produtos de comércio eletrônico necessárias para obter um desempenho satisfatório em todas as categorias de produtos.
Para resolver esse problema, este post mostra como prever atributos de produtos específicos do domínio a partir de imagens de produtos, refinando um VLM em um conjunto de dados de moda usando o Amazon SageMaker, e, em seguida, usando o Amazon Bedrock para gerar descrições de produtos usando os atributos previstos como entrada. Para que você possa acompanhar, estamos compartilhando o código em um repositório do GitHub.
O Amazon Bedrock é um serviço totalmente gerenciado que oferece uma escolha de modelos de base de alto desempenho (FMs) de empresas líderes em IA, como AI21 Labs, Anthropic, Cohere, Meta, Stability AI e Amazon, através de uma única API, juntamente com um amplo conjunto de recursos de que você precisa para construir aplicativos de IA gerativa com segurança, privacidade e IA responsável.
Você pode usar um serviço gerenciado, como o Amazon Rekognition, para prever atributos de produtos, conforme explicado em Automatizando a geração de descrição de produtos com o Amazon Bedrock.
No entanto, se você estiver tentando extrair especificidades e características detalhadas do seu produto ou do seu domínio (setor), o refinamento de um VLM no Amazon SageMaker é necessário.
Modelos de linguagem-visão
Desde 2021, tem havido um aumento do interesse em modelos de linguagem-visão (VLMs), o que levou ao lançamento de soluções como Contrastive Language-Image Pre-training (CLIP) e Bootstrapping Language-Image Pre-training (BLIP). Quando se trata de tarefas como legenda de imagens, geração de imagens guiada por texto e resposta visual a perguntas, os VLMs demonstraram desempenho de ponta.
Neste post, usamos o BLIP-2, que foi apresentado em BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models, como nosso VLM. O BLIP-2 consiste em três modelos: um codificador de imagens semelhante ao CLIP, um Transformador de Consulta (Q-Former) e um grande modelo de linguagem (LLM). Usamos uma versão do BLIP-2 que contém o Flan-T5-XL como o LLM.
O diagrama a seguir ilustra a visão geral do BLIP-2:
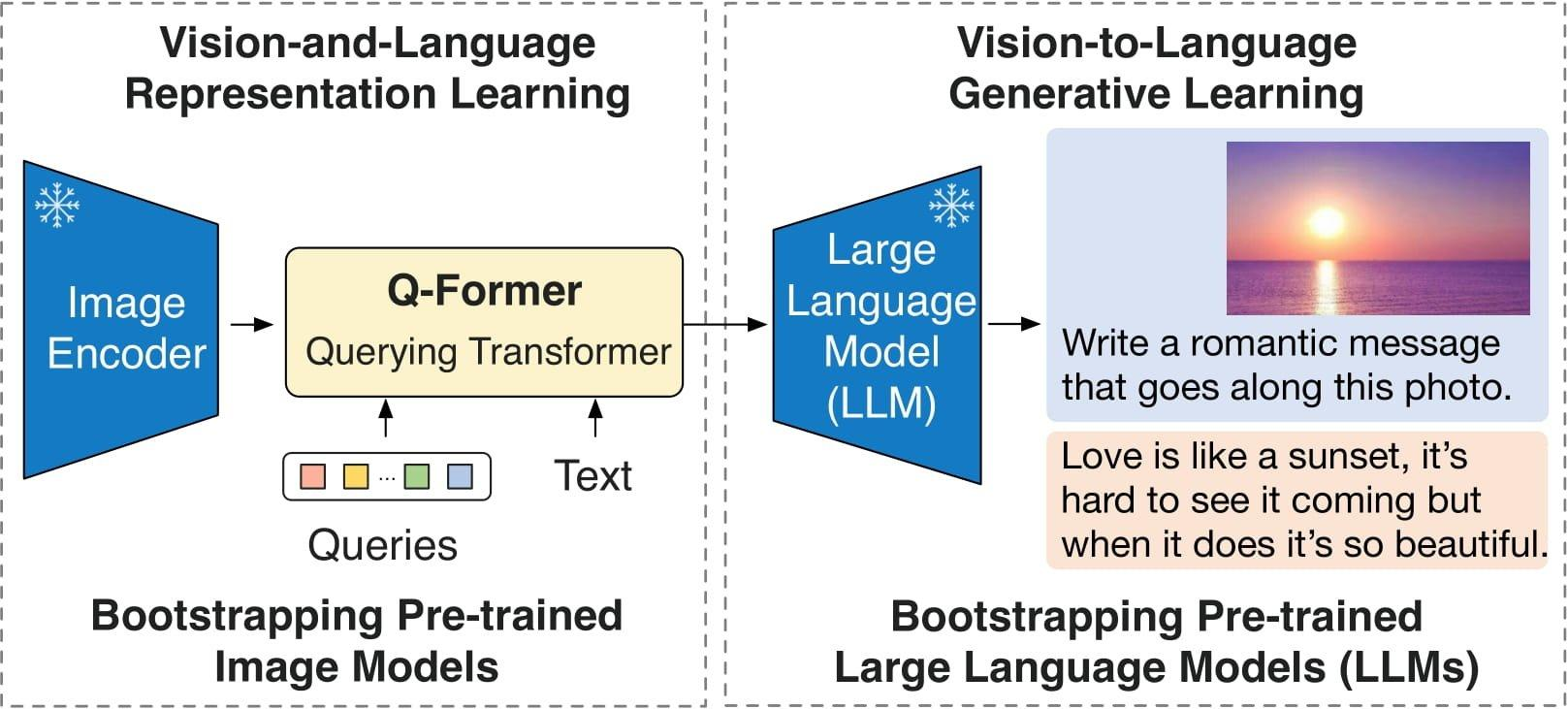
Figura 1: Visão geral do BLIP-2
Neste post, demonstramos como ajustar finamente o BLIP-2 para um caso de uso específico de domínio.
Visão geral da solução
O diagrama a seguir ilustra a arquitetura da solução.
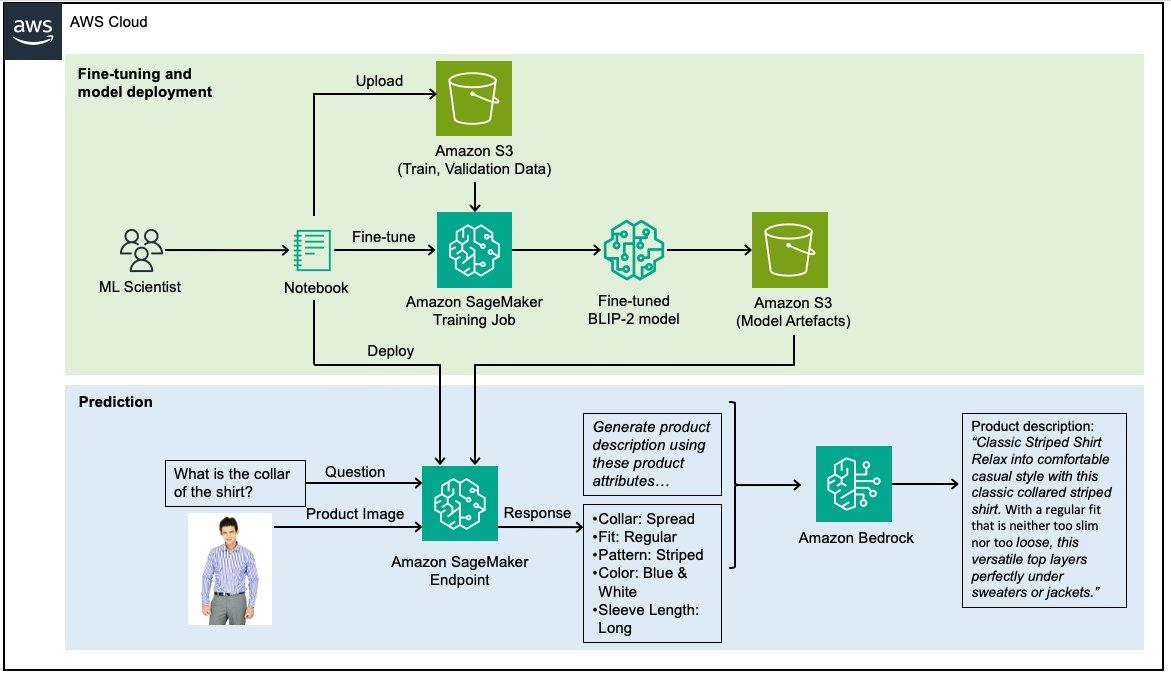
Figura 2: Arquitetura de solução de alto nível
A visão geral de alto nível da solução é:
- Um cientista de ML usa os cadernos do Sagemaker para processar e dividir os dados em dados de treinamento e validação.
- Os conjuntos de dados são carregados no Amazon Simple Storage Service (Amazon S3) usando o cliente S3 (um wrapper em torno de uma chamada HTTP).
- Em seguida, o cliente Sagemaker é usado para iniciar um trabalho de treinamento do Sagemaker, novamente um wrapper para uma chamada HTTP.
- O trabalho de treinamento gerencia a cópia dos conjuntos de dados do S3 para o contêiner de treinamento, o treinamento do modelo e o salvamento de seus artefatos no S3.
- Então, por meio de outra chamada do cliente Sagemaker, um endpoint é gerado, copiando os artefatos do modelo para o contêiner de hospedagem do endpoint.
- O fluxo de trabalho de inferência é então invocado por meio de uma solicitação AWS Lambda, que primeiro faz uma solicitação HTTP para o endpoint do Sagemaker e, em seguida, usa isso para fazer outra solicitação ao Amazon Bedrock.
Nas seções a seguir, demonstramos como:
- Configurar o ambiente de desenvolvimento
- Carregar e preparar o conjunto de dados
- Afinar o modelo BLIP-2 para aprender atributos de produtos usando o SageMaker
- Implantar o modelo BLIP-2 afinado e prever atributos de produtos usando o SageMaker
- Gerar descrições de produtos a partir de atributos de produtos previstos usando o Amazon Bedrock
Configurar o ambiente de desenvolvimento
É necessário ter uma conta da AWS com uma função do AWS Identity and Access Management (IAM) que tenha permissões para gerenciar os recursos criados como parte da solução.
Nós utilizamos o Amazon SageMaker Studio com a instância ml.t3.medium e a imagem Data Science 3.0. No entanto, você também pode usar uma instância de notebook do Amazon SageMaker ou qualquer ambiente de desenvolvimento integrado (IDE) de sua escolha.
Uma instância ml.g5.2xlarge é usada para trabalhos de treinamento do SageMaker, e uma instância ml.g5.2xlarge é usada para endpoints do SageMaker.
Você precisa clonar este repositório do GitHub para replicar a solução demonstrada neste post.
Primeiro, inicie o notebook main.ipynb no SageMaker Studio selecionando a Imagem como Data Science e o Kernel como Python 3. Instale todas as bibliotecas necessárias mencionadas no requirements.txt.
Carregar e preparar o conjunto de dados
Para este post, utilizamos o Conjunto de Dados de Imagens de Moda do Kaggle, que contém 44.000 produtos com múltiplos rótulos de categoria, descrições e imagens de alta resolução. Neste post, queremos demonstrar como ajustar um modelo para aprender atributos como tecido, corte, colarinho, padrão e comprimento da manga de uma camisa usando a imagem e uma pergunta como entradas.
Cada produto é identificado por um ID, como 38642, e existe um mapeamento para todos os produtos em styles.csv. A partir daqui, podemos buscar a imagem para este produto em images/38642.jpg e os metadados completos em styles/38642.json. Para ajustar nosso modelo, precisamos converter nossos exemplos estruturados em uma coleção de pares de pergunta e resposta. Nosso conjunto de dados final tem o seguinte formato após o processamento de cada atributo:
Id | Question | Answer
38642 | Qual é o tecido da roupa nesta imagem? | Tecido: Algodão
Depois de processarmos o conjunto de dados, nós o dividimos em conjuntos de treinamento e validação, criamos arquivos CSV e carregamos o conjunto de dados no Amazon S3.
Ajuste fino do modelo BLIP-2 para aprender atributos de produtos usando o SageMaker
Para iniciar um trabalho de treinamento do SageMaker, precisamos do HuggingFace Estimator. O SageMaker inicia e gerencia todas as instâncias necessárias do Amazon Elastic Compute Cloud (Amazon EC2) para nós, fornece o contêiner apropriado do Hugging Face, faz o upload dos scripts especificados e baixa os dados do nosso bucket S3 para o contêiner em /opt/ml/input/data.
Ajustamos o BLIP-2 usando a técnica de Adaptação de Baixa Patente (Low Rank Adaptation, LoRA), que adiciona matrizes de decomposição de patente treináveis a cada camada de estrutura Transformer, mantendo os pesos do modelo pré-treinado em um estado estático.
Esta técnica pode aumentar a taxa de treinamento e reduzir a quantidade de RAM da GPU necessária em 3 vezes e o número de parâmetros treináveis em 10.000 vezes. Apesar de usar menos parâmetros treináveis, o LoRA demonstrou ter um desempenho tão bom ou melhor do que a técnica de ajuste fino completa.
Preparamos o entrypoint_vqa_finetuning.py que implementa o ajuste fino do BLIP-2 com a técnica LoRA usando Hugging Face Transformers, Accelerate e Parameter-Efficient Fine-Tuning (PEFT). O script também mescla os pesos do LoRA nos pesos do modelo após o treinamento. Como resultado, você pode implantar o modelo como um modelo normal sem nenhum código adicional.
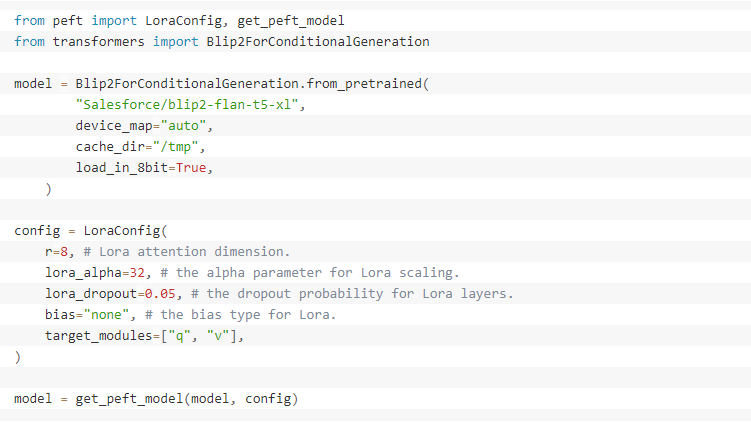
Referenciamos entrypoint_vqa_finetuning.py como o ponto de entrada no Estimador Hugging Face.

Podemos iniciar nosso trabalho de treinamento executando o método .fit() e passando nosso caminho do Amazon S3 para as imagens e nosso arquivo de entrada.

Implementar o modelo BLIP-2 ajustado e prever os atributos do produto usando o SageMaker
Implantamos o modelo BLIP-2 ajustado no endpoint em tempo real do SageMaker usando o Contêiner de Inferência HuggingFace. Você também pode usar o contêiner de inferência do modelo grande (LMI), que é descrito com mais detalhes em Construir uma solução de moderação de conteúdo baseada em IA generativa no Amazon SageMaker JumpStart, que implanta um modelo BLIP-2 pré-treinado. Aqui, fazemos referência ao nosso modelo ajustado no Amazon S3 em vez do modelo pré-treinado disponível no hub da Hugging Face. Primeiro, criamos o modelo e implantamos o endpoint.
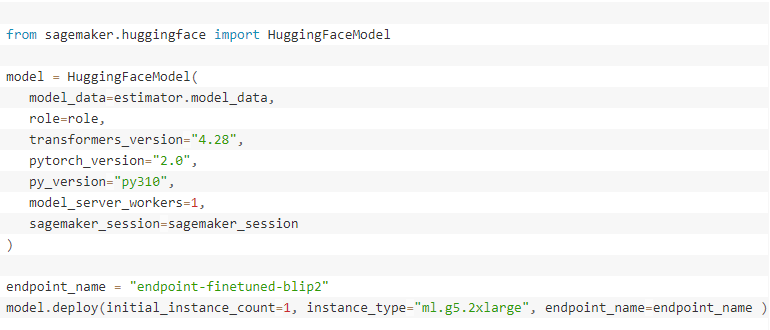
Quando o status do endpoint se tornar in service, podemos invocar o endpoint para a tarefa de geração de visão para linguagem instruída com uma imagem de entrada e uma pergunta como um prompt:

A resposta de saída parece o seguinte:
{“Sleeve Length”: “Long Sleeves”}
Gerar descrições de produtos a partir de atributos de produtos previstos usando o Amazon Bedrock
Para começar com o Amazon Bedrock, solicite acesso aos modelos fundamentais (eles não estão habilitados por padrão). Você pode seguir os passos na documentação para habilitar o acesso ao modelo. Neste post, usamos o Claude da Anthropic no Amazon Bedrock para gerar descrições de produtos. Especificamente, utilizamos o modelo anthropic.claude-3-sonnet-20240229-v1 porque ele oferece bom desempenho e velocidade.
Após criar o cliente boto3 para o Amazon Bedrock, criamos uma string de prompt que especifica que queremos gerar descrições de produtos usando os atributos do produto.
Você é um especialista em escrever descrições de produtos para camisetas. Use os dados abaixo para criar uma descrição de produto para um site. A descrição do produto deve conter todos os atributos fornecidos. Forneça algumas frases inspiradoras, por exemplo, sobre como o tecido se move. Pense no que um potencial cliente gostaria de saber sobre as camisetas. Aqui estão os fatos que você precisa para criar as descrições dos produtos: [Aqui inserimos os atributos previstos pelo modelo BLIP-2]
O prompt e os parâmetros do modelo, incluindo o número máximo de tokens usados na resposta e a temperatura, são passados para o corpo. A resposta JSON deve ser analisada antes que o texto resultante seja impresso na última linha.

A resposta gerada da descrição do produto parece o seguinte:
“Camisa Listrada Clássica Relaxe no estilo casual confortável com esta clássica camisa listrada com colarinho. Com um corte regular que não é nem muito justo nem muito solto, esta blusa versátil combina perfeitamente por baixo de suéteres ou casacos.”
Conclusão
Mostramos como a combinação de VLMs no SageMaker e LLMs no Amazon Bedrock apresentam uma solução poderosa para automatizar a geração de descrições de produtos de moda. Ao ajustar o modelo BLIP-2 em um conjunto de dados de moda usando o Amazon SageMaker, você pode prever atributos de produtos específicos do domínio e nuances diretamente a partir de imagens.
Em seguida, utilizando as capacidades do Amazon Bedrock, você pode gerar descrições de produtos a partir dos atributos de produtos previstos, aprimorando a capacidade de busca e personalização das plataformas de comércio eletrônico.
À medida que continuamos a explorar o potencial da IA generativa, os LLMs e VLMs surgem como uma via promissora para revolucionar a geração de conteúdo no cenário em constante evolução do varejo online.
DNX Brasil: sua parceira para projetos de alto nível de GenAI
Somos Premier Partner da AWS, com diversas competências e equipes especializadas em inteligência artificial e IA generativa.
Nossa expertise nos capacita a desenvolver soluções personalizadas com o Amazon Bedrock e Amazon SageMaker para ajudar nossos clientes a otimizar operações, gerar novos negócios e explorar possibilidades de lucratividade.
Os cases de sucesso da Alfaneo, da IndeCX e da Unxpose mostram não só o potencial da GenAI, mas também como a DNX Brasil implementou ferramentas avançadas em projetos que foram além das expectativas.
Se você quer a mesma evolução na sua empresa, entre em contato com nossos consultores!
*Artigo adaptado e traduzido a partir do blog da AWS.
Artigos relacionados

18
jul




01
jul


27
jun


19
jun


07
jun

05
jun
