











Os recentes avanços da IA generativa estão elevando o nível de ferramentas que podem ajudar as startups a criar, escalar e inovar rapidamente.
A ampla adoção e democratização do machine learning (ML), especificamente com a arquitetura de rede neural do transformador, é um ponto de inflexão empolgante na tecnologia. Com as ferramentas certas, as startups podem desenvolver novas ideias ou otimizar seus produtos existentes para aproveitar os benefícios da IA generativa para seus clientes.
Para ajudar você a saber mais sobre como criar uma aplicação de GenAI para sua startup, vamos começar analisando os conceitos, as ideias principais e as abordagens comuns referentes ao tema.
O que são aplicações de IA generativa?
As aplicações de GenAI são programas baseados em um tipo de IA que possa criar novos conteúdos e ideias, incluindo conversas, histórias, imagens, vídeos, códigos e músicas. Assim como todos os programas de inteligência artificial, as aplicações de IA generativa são alimentadas por modelos de ML pré-treinados em grandes quantidades de dados e comumente chamados de modelos de base (FMs).
Um exemplo de aplicação de IA generativa é o Amazon CodeWhisperer, um companheiro de codificação de IA que ajuda os desenvolvedores a criar aplicações com mais rapidez e segurança, fornecendo sugestões de código de função e linha completa em seu ambiente de desenvolvimento integrado (IDE).
O CodeWhisperer é treinado em bilhões de linhas de código e pode gerar sugestões de código que variam de trechos a funções completas instantaneamente, com base em seus comentários e no código existente. 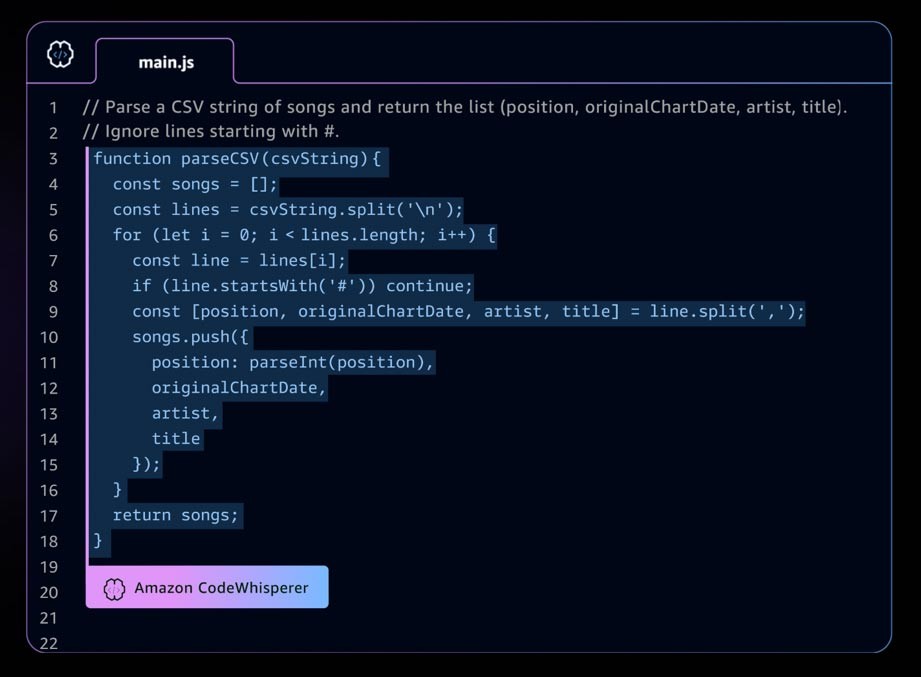
Figura 1: O CodeWhisperer da Amazon escreve um código JavaScript usando comentários como prompt.
O cenário de IA generativa em rápido desenvolvimento
Há um rápido crescimento ocorrendo em startups de IA generativa e também em startups que criam ferramentas para simplificar a adoção da IA generativa.
Ferramentas como o LangChain, uma estrutura de código aberto para o desenvolvimento de aplicações alimentadas por modelos de linguagem, estão tornando a IA generativa mais acessível a mais organizações. O resultado é a adoção mais rápido dessa tecnologia.
Tais ferramentas também incluem engenharia de prompts, serviços de ampliação (como ferramentas de incorporação ou bancos de dados de vetores), monitoramento de modelos, medição da qualidade do modelo, barreiras de proteção, anotação de dados, aprendizado reforçado com base em feedback humano (RLHF) e muito mais.
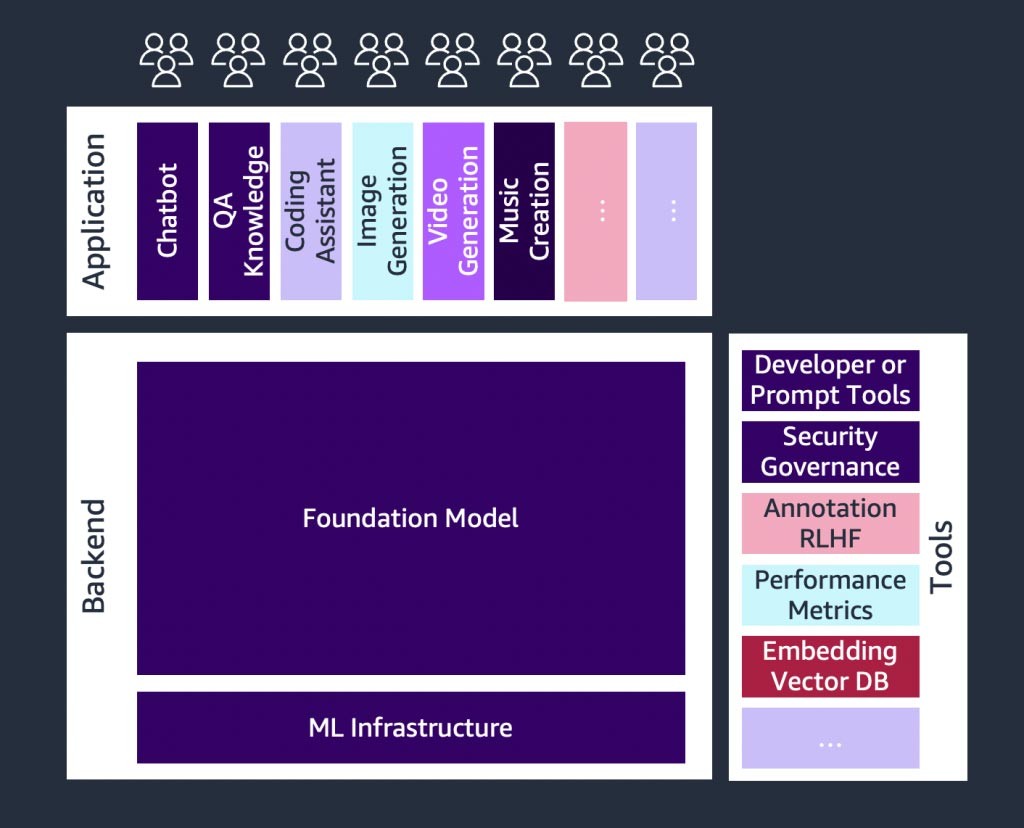
Figura 2: Componentes do cenário de inteligência artificial generativa.
Uma introdução aos modelos de base
O núcleo de uma aplicação ou ferramenta de IA generativa é o modelo de base.
Os modelos de base são uma classe de modelos poderosos de machine learning que se diferenciam pela capacidade de serem pré-treinados em grandes quantidades de dados para realizar uma ampla variedade de tarefas downstream. Essas tarefas incluem geração de texto, resumo, extração de informações, perguntas e respostas e/ou chatbots.
Por outro lado, os modelos tradicionais de ML são treinados para realizar uma tarefa específica a partir de um conjunto de dados.
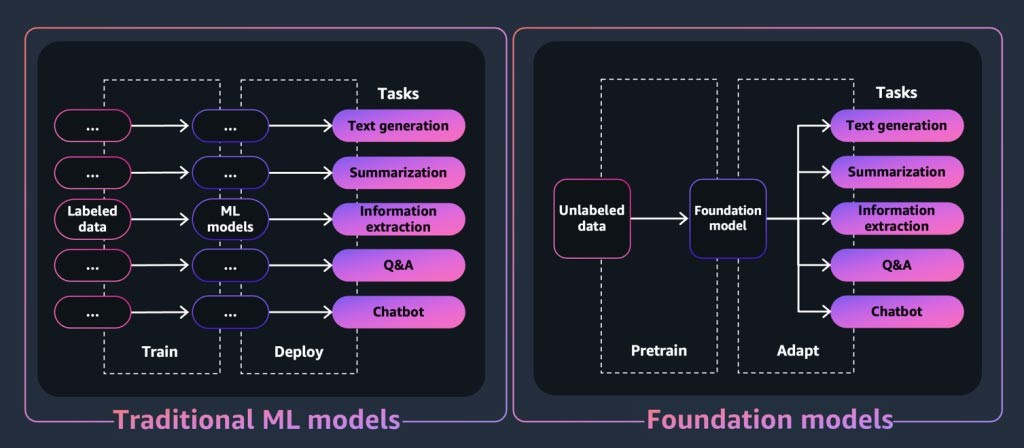
Figura 3: Demonstração da diferença entre um modelo de ML tradicional e um modelo de base.
Então, como um modelo de base “gera” a saída pela qual as aplicações de IA generativa são conhecidas?
Esses recursos resultam de padrões e relacionamentos de aprendizado que permitem ao FM prever o próximo item ou itens em uma sequência ou gerar um novo:
- Nos modelos de geração de texto, os FMs produzem a próxima palavra, a próxima frase ou a resposta a uma pergunta.
- Para modelos de geração de imagens, os FMs produzem uma imagem com base no texto.
- Quando uma imagem é uma entrada, os FMs produzem a próxima imagem, animação ou imagens 3D relevantes ou aprimoradas.
Em cada caso, o modelo começa com um vetor inicial derivado de um “prompt”: os prompts descrevem a tarefa que o modelo deve realizar. A qualidade e os detalhes (também conhecidos como “contexto”) do prompt determinam a qualidade e a relevância da saída.
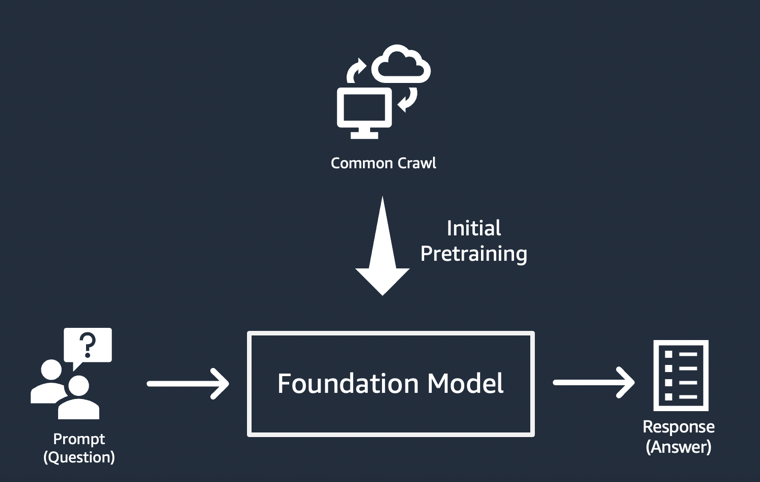
Figura 4: Um usuário insere um prompt em um modelo de base e ele gera uma resposta.
A implementação mais simples de aplicações de IA generativa
A abordagem mais simples para criar uma aplicação de IA generativa é usar um modelo de base ajustado às instruções e fornecer um prompt significativo (“engenharia de prompt”) usando aprendizado zero-shot ou few-shot.
Um modelo ajustado às instruções (como FLAN T5 XXL, Open-Llama ou Falcon 40B Instruct) usa sua compreensão de tarefas ou conceitos relacionados para gerar previsões para prompts.
Veja alguns exemplos de prompts:
Aprendizado zero-shot

Aprendizado few-shot

As startups, em particular, podem se beneficiar da rápida implantação, das necessidades mínimas de dados e da otimização de custos resultantes do uso de um modelo ajustado às instruções.
Personalização de modelos de base
Nem todos os casos de uso podem ser atendidos usando engenharia de prompts em modelos ajustados a instruções.
Os motivos para personalizar um modelo de base para sua startup podem incluir:
- Adicionar uma tarefa específica (como geração de código) ao modelo de base;
- Gerar respostas com base no conjunto de dados proprietário da sua empresa;
- Buscar respostas geradas com base em conjuntos de dados de maior qualidade do que aqueles que pré-treinaram o modelo;
- Reduzir a “alucinação”, que é um resultado que não é factualmente correto ou razoável.
Há três técnicas comuns para personalizar um modelo de base.
1) Ajuste fino baseado em instruções
Essa técnica envolve treinar o modelo de base para concluir uma tarefa específica, com base em um conjunto de dados rotulado específico da mesma.
Um conjunto de dados rotulado consiste em pares de prompts e respostas. Essa técnica de personalização é benéfica para startups que desejam personalizar seu FM rapidamente e com um conjunto de dados mínimo: são necessários menos conjuntos de dados e etapas para treinar.
Os pesos do modelo são atualizados com base na tarefa ou na camada que você está ajustando.
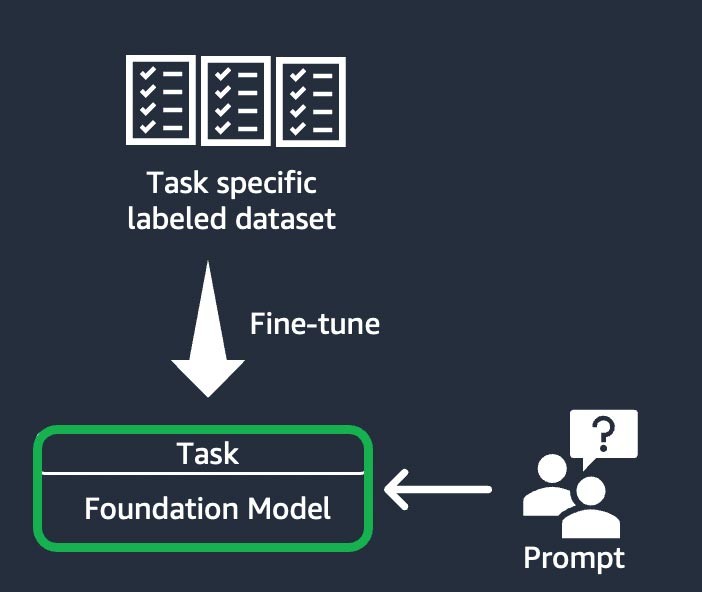
Figura 5: O fluxo de trabalho de ajuste fino baseado em instruções.
2) Adaptação do domínio (também conhecida como “pré-treinamento adicional”)
Esta técnica envolve o treinamento do modelo de base usando um grande “corpus”, um conjunto de materiais de treinamento, de dados não rotulados específicos do domínio (conhecido como “aprendizado auto-supervisionado”).
Ela beneficia casos de uso que incluem jargões específicos do domínio e dados estatísticos que o modelo de base existente nunca viu antes.
Por exemplo, startups que criam uma aplicação de IA generativa para trabalhar com dados proprietários no domínio financeiro podem se beneficiar de um pré-treinamento adicional do FM em vocabulário personalizado e da “tokenização”, um processo de dividir o texto em unidades menores chamadas tokens.
Para obter maior qualidade, algumas startups implementam técnicas de aprendizado reforçado com base em feedback humano (RLHF) nesse processo. Além disso, será necessário um ajuste fino baseado em instruções para ajustar uma tarefa específica. Essa é uma técnica cara e demorada em comparação com as outras. Os pesos do modelo são atualizados em todas as camadas.
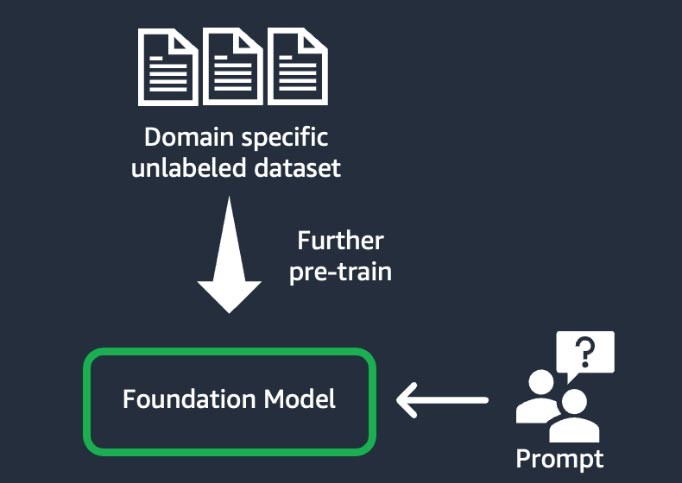
Figura 6: O fluxo de trabalho de adaptação de domínio.
3) Recuperação de informações (também conhecida como “geração aumentada de recuperação” ou “RAG”)
Esta técnica aumenta o modelo de base com um sistema de recuperação de informações baseado na representação de vetores densos.
O conhecimento de domínio fechado ou os dados proprietários passam por um processo de incorporação de texto para gerar uma representação de vetores do corpus e são armazenados em um banco de dados de vetores.
Um resultado de pesquisa semântica baseado na consulta do usuário se torna o contexto do prompt. O modelo de base é usado para gerar uma resposta com base na solicitação com contexto.
Nessa técnica, o peso do modelo de base não é atualizado.
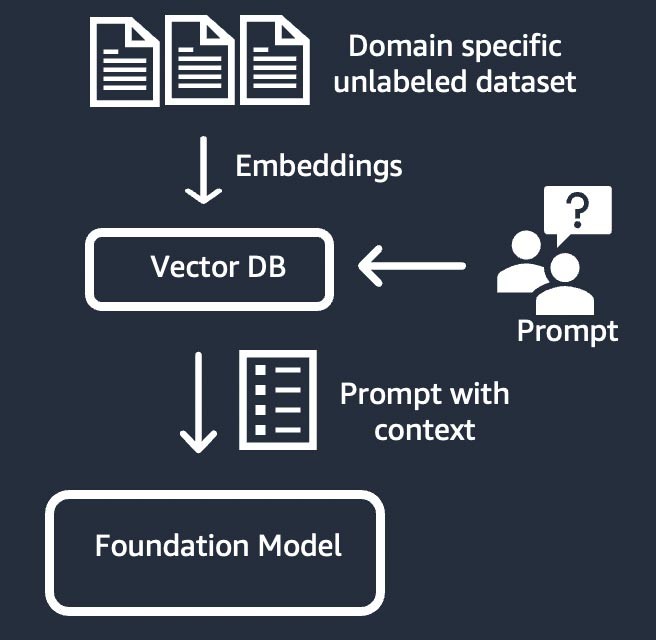
Figura 7: O workflow RAG.
Componentes de uma aplicação de IA generativa
Nas seções acima, aprendemos várias abordagens que as startups podem adotar com modelos de base ao criar aplicações de IA generativa. Agora, vamos analisar como esses modelos de base fazem parte dos ingredientes ou componentes típicos necessários para criar uma aplicação de GenAI.
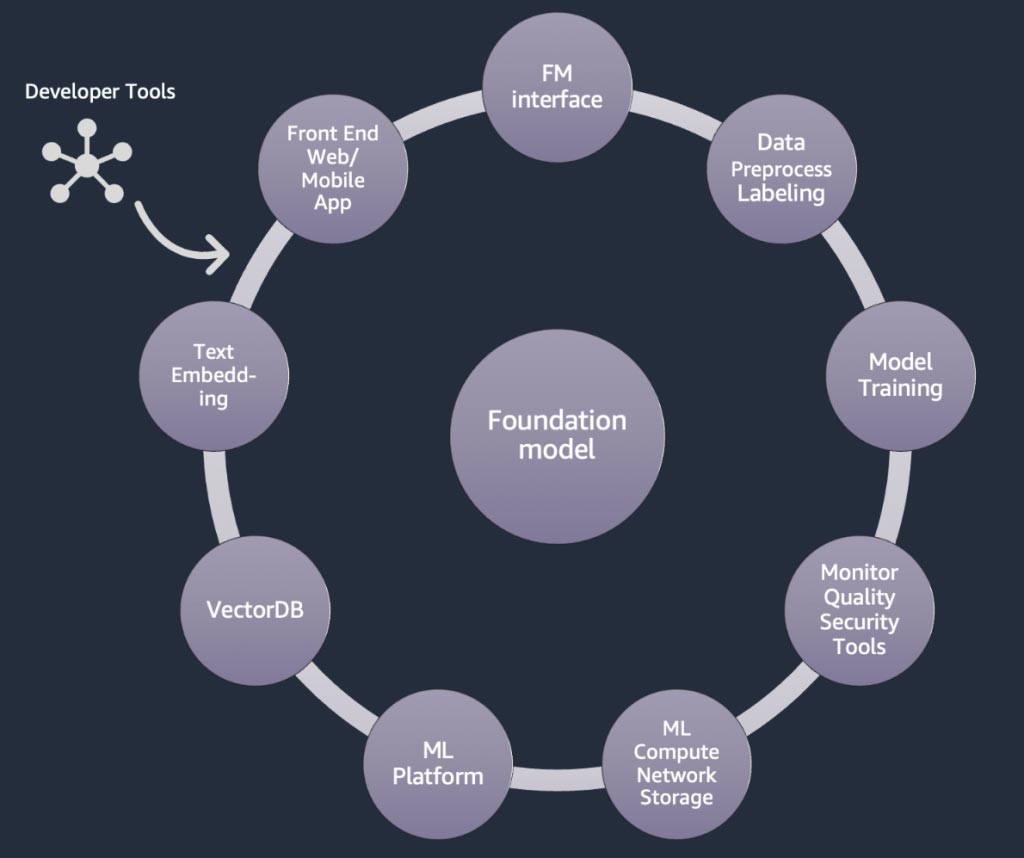
Figura 8: Componentes de uma aplicação de IA generativa.
No núcleo está um modelo de base (centro). Na abordagem mais simples discutida anteriormente neste blog, isso requer uma aplicação Web ou aplicativo móvel (canto superior esquerdo) que acesse o modelo de base por meio de uma API (parte superior).
Essa API é um serviço gerenciado por meio de um provedor de modelos ou auto-hospedado usando um modelo proprietário ou de código aberto. No caso de auto-hospedagem, você pode precisar de uma plataforma de machine learning que seja suportada por instâncias com computação acelerada para hospedar o modelo.
Na técnica RAG, você precisará adicionar um endpoint de incorporação de texto e um banco de dados de vetores (esquerdo e inferior esquerdo). Ambos são fornecidos como um serviço de API ou são auto-hospedados.
O endpoint de incorporação de texto é respaldado por um modelo de base, e a escolha do modelo de base depende da lógica de incorporação e do suporte à tokenização.
Todos esses componentes são conectados entre si usando ferramentas de desenvolvedor, que fornecem a estrutura para o desenvolvimento de aplicações de IA generativa.
E, por fim, quando você escolhe as técnicas de personalização de ajuste fino ou pré-treinamento adicional de um modelo de base (à direita), precisa de componentes que ajudem no pré-processamento e na anotação de dados (canto superior direito) e de uma plataforma de ML (parte inferior) para executar o trabalho de treinamento em instâncias com computação acelerada específicas.
Alguns fornecedores de modelos oferecem suporte ao ajuste fino baseado em API e, nesses casos, você não precisa se preocupar com a plataforma de ML e o hardware subjacente.
Independentemente da abordagem de personalização, talvez você também queira integrar componentes que forneçam monitoramento, métricas de qualidade e ferramentas de segurança (canto inferior direito).
Quais serviços da AWS devo usar para criar minha aplicação de IA generativa?
O diagrama a seguir, Figura 9, mapeia cada componente para o(s) serviço(s) correspondente(s) da AWS. Observe que apenas algumas ferramentas foram selecionadas como sugestão. No entanto, existem outros serviços da Amazon Web Services disponíveis.
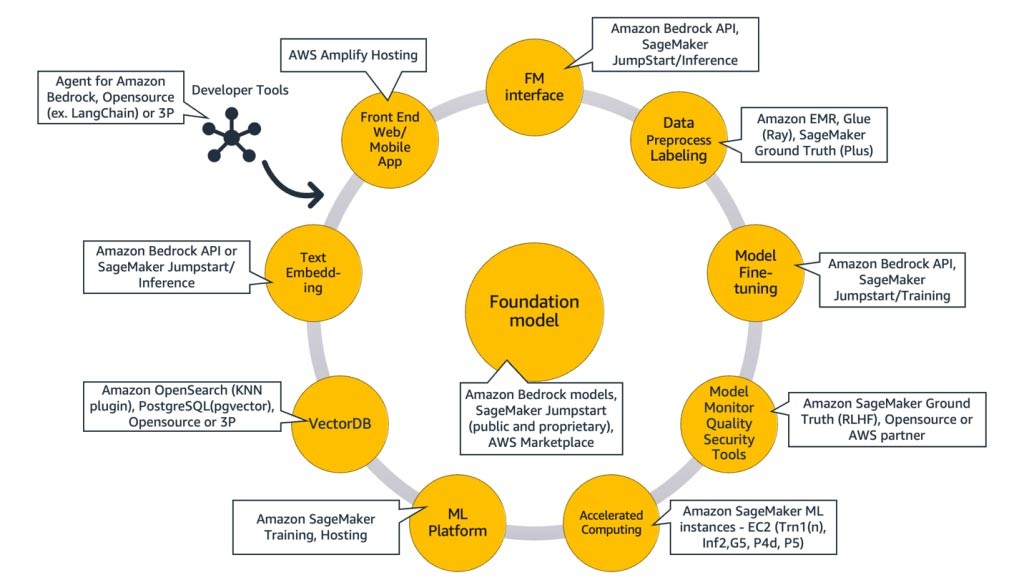
Figura 9: Mapeando serviços AWS para componentes de IA generativa.
Para explicar melhor, vamos começar mapeando os serviços da AWS para os componentes comuns de uma aplicação de IA generativa. Em seguida, falaremos sobre os serviços da AWS que são mapeados para os componentes restantes na Figura 9, com base nas abordagens que você pode usar para implementar sua aplicação.
Componentes comuns
Os componentes comuns de uma aplicação de IA generativa são o modelo de base (FM), sua interface e, opcionalmente, a plataforma de machine learning (ML) e a computação acelerada.
Eles podem ser atendidos pelos seguintes serviços da AWS:
Amazon Bedrock (modelo de base e seus componentes de interface)
O Amazon Bedrock, é um serviço totalmente gerenciado que disponibiliza Foundation Models (FMs) das principais startups de IA (Jurassic da AI21, Claude da Anthropic, Command and Embedding da Cohere, modelos SDXL da Stability) e da Amazon (modelos Titan Text e Embeddings) via API, para que você possa escolher entre uma ampla variedade de FMs para encontrar o modelo mais adequado ao seu caso de uso.
O Amazon Bedrock fornece API ou acesso com tecnologia sem servidor a um conjunto de modelos de base para fornecer três recursos: incorporação de texto, solicitação/resposta e ajuste fino (em modelos selecionados).
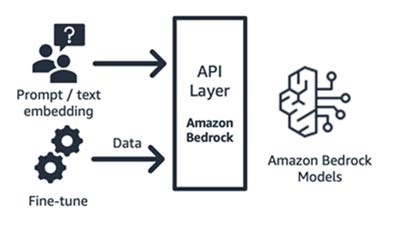
Figura 10: Workflow do Amazon Bedrock
O Amazon Bedrock é ideal para startups de consumidores de aplicações ou modelos que estão criando serviços de valor agregado, engenharia rápida, geração de recuperação aumentada e muito mais, em torno de um modelo de base de sua escolha.
Amazon SageMaker JumpStart (modelo de base e seus componentes de interface)
A AWS oferece recursos de IA generativa ao Amazon SageMaker Jumpstart: um hub de modelo de base contendo modelos proprietários e disponíveis publicamente, soluções de início rápido e exemplos de cadernos para implantar e ajustar modelos. Quando você implanta esses modelos, ele cria um endpoint de inferência em tempo real que você pode acessar diretamente usando o SDK/API do SageMaker. Ou você pode usar o front-end do modelo de base do SageMaker com o AWS API Gateway e uma lógica computacional leve em uma função do AWS Lambda.
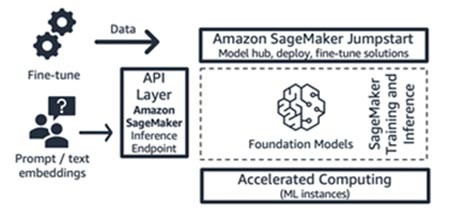
Figura 11: Workflow do Amazon SageMaker
Tanto o endpoint de inferência quanto os trabalhos de treinamento de ajuste fino são executados nas instâncias de ML gerenciadas de sua escolha (veja “Computação acelerada” na Figura 9) usando o SageMaker como plataforma de ML (veja “Plataforma de ML” na Figura 9).
O SageMaker Jumpstart é ideal para startups consumidoras de aplicações ou modelos que desejam mais controle sobre sua infraestrutura e que têm habilidades moderadas de ML e conhecimento de infraestrutura.
Treinamento e inferência do Amazon SageMaker (plataforma de ML)
As startups podem aproveitar os recursos de treinamento e inferência do Amazon SageMaker para obter recursos avançados, como treinamento distribuído, inferência distribuída, endpoints multimodelos e muito mais. Você pode trazer os modelos de base do hub de modelos de sua escolha, seja o SageMaker JumpStart, o Hugging Face ou o AWS Marketplace, ou pode criar seu próprio modelo de base do zero.
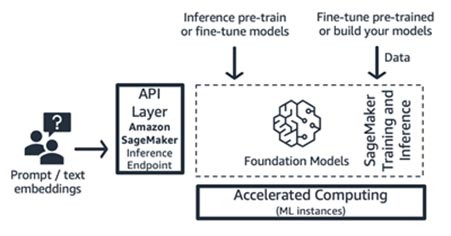
Figura 12: Fluxo de trabalho de treinamento e inferência do Amazon SageMaker
O SageMaker é adequado para criadores de aplicações de IA generativa de pilha completa (de fornecedores de modelos a consumidores de modelos) ou para fornecedores de modelos com equipes que têm habilidades avançadas de ML e pré-processamento de dados.
AWS Trainium e AWS Inferentia (computação acelerada)
Em abril de 2023, a AWS anunciou a disponibilidade geral das instâncias do Amazon EC2 Trn1n baseadas no AWS Trainium e das instâncias Amazon EC2 Inf2 baseadas no AWS Inferentia2.
Você pode aproveitar os aceleradores específicos da AWS (AWS Trainium e AWS Inferentia) usando o SageMaker como plataforma de ML.
O teste de benchmark para workloads de inferência relata que as instâncias Inf2 funcionam com custos 52% mais baixos em comparação com uma instância comparável do Amazon EC2 otimizada para inferência.
Sugerimos ficar de olho nos ciclos rápidos de desenvolvimento do AWS Neuron SDK, em que aproximadamente todo mês a AWS adiciona uma nova arquitetura de modelo em sua matriz de suporte para treinamento e inferência.
Abordagens para criar aplicações de IA generativa
Agora, vamos discutir cada um dos componentes na Figura 9 com base em uma perspectiva de implementação.
A abordagem de inferência de aprendizado zero-shot ou few-shot
Como discutimos anteriormente, o aprendizado zero-shot ou few-shot é a abordagem mais simples para criar uma aplicação de IA generativa.
Para criar aplicações com base nessa abordagem, tudo o que você precisa são os serviços para os quatro componentes comuns (modelo de base, sua interface, plataforma de ML e computação), seu código personalizado para gerar prompts e um aplicativo Web/móvel front-end.
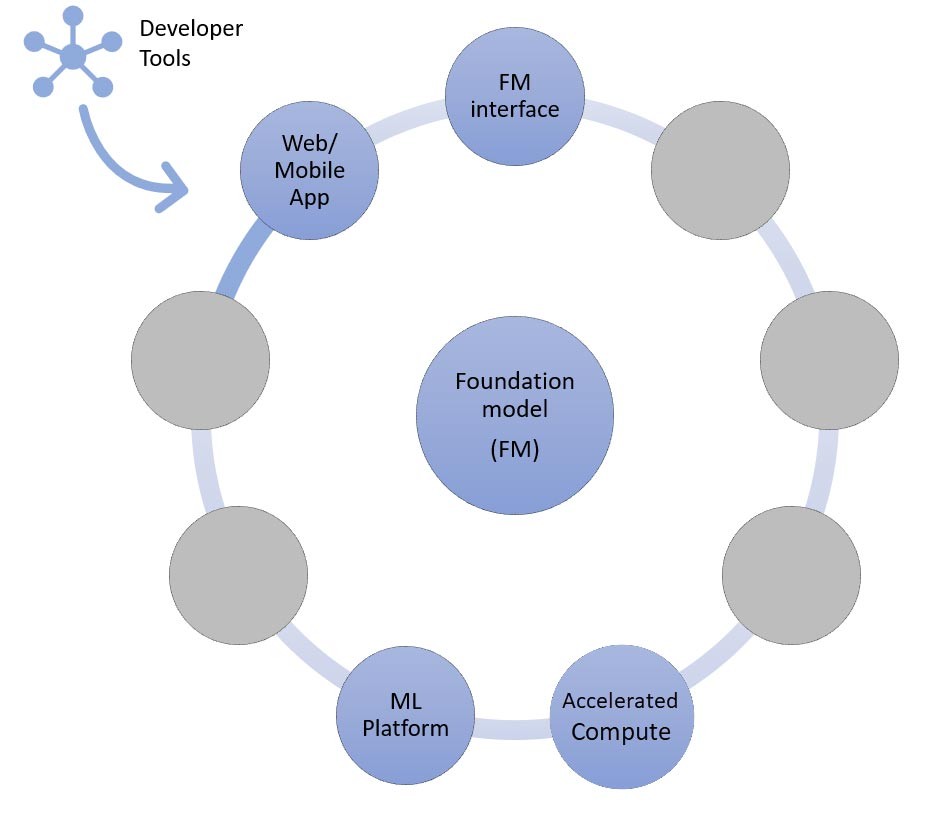
Figura 13: Componentes da abordagem de aprendizado de tiro zero
O código personalizado pode aproveitar ferramentas de desenvolvedor, como o LangChain para geração e modelos imediatos. A comunidade LangChain já adicionou suporte para endpoints Amazon Bedrock, Amazon API Gateway e SageMaker. Você também queira usar o AWS Amazon CodeWhisperer, uma ferramenta complementar de codificação, para ajudar a melhorar a eficiência dos desenvolvedores.
Startups que criam um aplicativo Web front-end ou aplicativo móvel podem facilmente começar e escalar usando o AWS Amplify e hospedar esses aplicativos Web de forma rápida, segura e confiável usando o AWS Amplify Hosting.
A abordagem de recuperação de informações
Conforme discutimos mais acima, uma das maneiras pelas quais sua startup pode personalizar os modelos de base é por meio do aumento com um sistema de recuperação de informações, mais conhecido como geração aumentada de recuperação (RAG).
Essa abordagem envolve todos os componentes mencionados no aprendizado zero-shot e few-shot, bem como o endpoint de incorporação de texto e o banco de dados vetoriais.
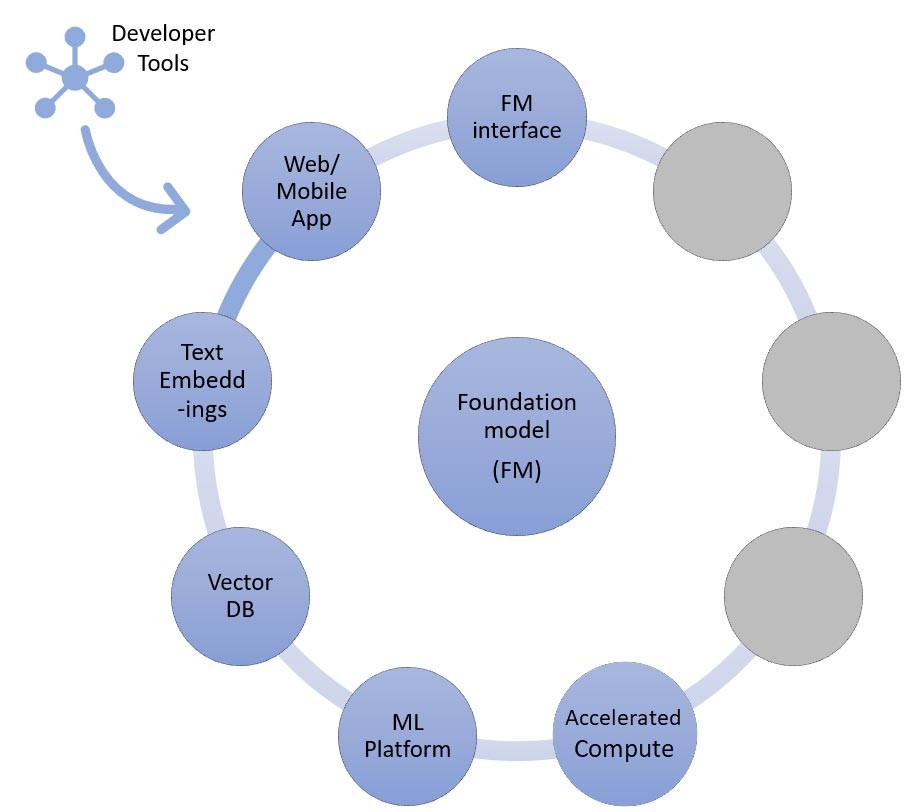
Figura 14: Componentes da abordagem de recuperação de informações
As opções para o endpoint de incorporação de texto variam dependendo do serviço gerenciado da AWS que você selecionou:
- O Amazon Bedrock oferece um grande modelo de linguagem (LLM) de incorporações que traduz entradas de texto (palavras, frases ou possivelmente grandes unidades de texto) em representações numéricas (conhecidas como incorporações) que contêm o significado semântico do texto.
- Se estiver usando o SageMaker JumpStart, é possível hospedar um modelo de incorporação como o GPT-J 6B ou qualquer outro LLM de sua escolha usando o hub de modelos. O endpoint do SageMaker pode ser invocado pelo SDK do SageMaker ou pelo Boto3 para traduzir entradas de texto em incorporações.
As incorporações podem, então, ser armazenadas em um datastore vetorial para fazer pesquisas semânticas usando a extensão pgvector do Amazon RDS para PostgreSQL ou o plug-in k-NN do Amazon OpenSearch Service.
As startups preferem um ou outro com base no serviço que normalmente se sentem mais à vontade de usar. Em alguns casos, as startups usam bancos de dados de vetores nativos de IA de parceiros da AWS ou de código aberto.
Também nessa abordagem, as ferramentas do desenvolvedor desempenham uma função fundamental. Eles fornecem uma estrutura plug-n-play fácil, modelos rápidos e amplo suporte para integrações.
A abordagem de ajuste fino ou de pré-treinamento adicional
Agora, vamos mapear os componentes dos serviços da AWS necessários para a última abordagem de implementação de uma aplicação de IA generativa: ajuste fino ou pré-treinamento adicional de um modelo de base.
Essa abordagem envolve todos os componentes discutidos no aprendizado zero-shot ou few-shot, bem como o pré-processamento de dados e o treinamento de modelos.
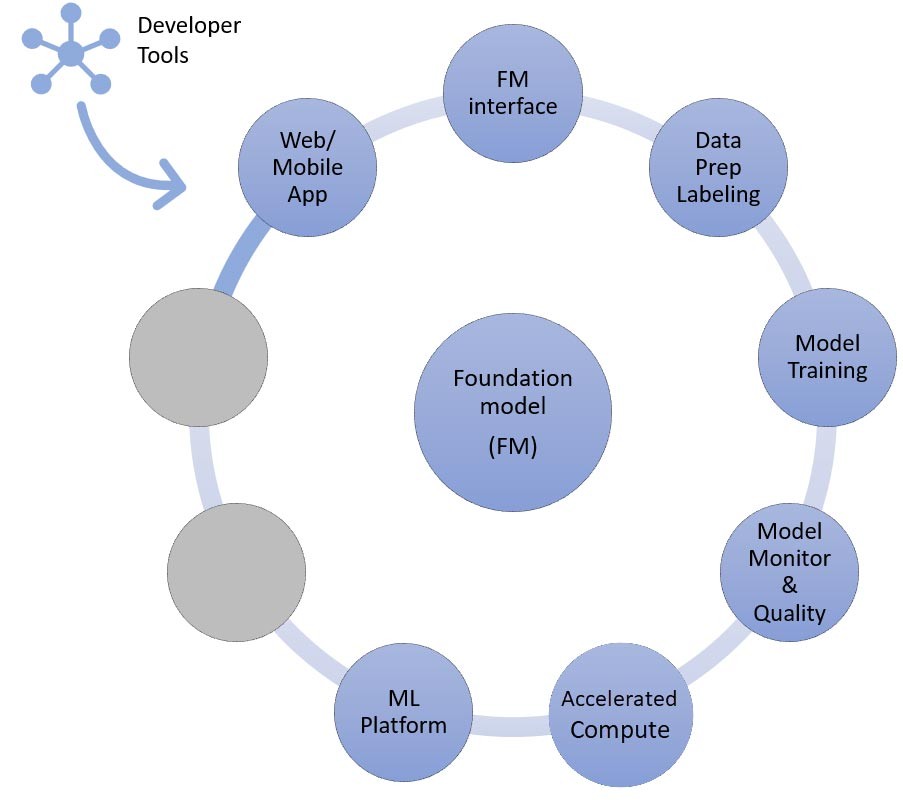
Figura 15: Componentes da abordagem de ajuste fino ou pré-treinamento adicional
A preparação de dados (às vezes chamada de pré-processamento ou anotação) é particularmente importante durante o ajuste fino, onde você precisa de conjuntos de dados menores e rotulados.
As startups podem começar facilmente a usar o Amazon SageMaker Data Wrangler. Esse serviço ajuda a reduzir o tempo necessário para agregar e preparar dados tabulares e de imagem para machine learning, de semanas para minutos.
Também é possível aproveitar o atributo de pipeline de inferência desse serviço para encadear o workflow de pré-processamento a trabalhos de treinamento ou ajuste fino.
Se sua startup precisar pré-processar um grande corpus de conjunto de dados não estruturados e sem rótulos em seu data lake no Amazon S3, existem algumas opções:
- Se estiver usando Python e bibliotecas populares Python, é útil aproveitar o AWS Glue for Ray. O AWS Glue usa o Ray, uma estrutura computacional unificada de código aberto usada para escalar workloads do Python.
- Como alternativa, o Amazon EMR pode ajudar a processar grandes quantidades de dados usando ferramentas de código aberto, como o Apache Spark, o Apache Hive, o Apache HBase, o Apache Flink, o Apache Hudi e o Presto.
Para o componente de treinamento de modelos dessa abordagem, o Amazon Bedrock permite que você personalize FMs de forma privada com seus próprios dados. Ele gerencia suas FMs em escala sem precisar gerenciar nenhuma infraestrutura (essa é a forma de ajuste fino da API).
Como alternativa, a abordagem SageMaker Jumpstart fornece uma solução de início rápido para ajustar de forma privada (em modelos selecionados) para instrução ou adaptação de domínio, usando seus próprios dados.
Você pode modificar o script de treinamento incluído do SageMaker JumpStart de acordo com suas necessidades ou pode trazer seus próprios scripts de treinamento para modelos de código aberto e enviá-los como um trabalho de treinamento do SageMaker.
Se você precisar pré-treinar ainda mais o modelo (normalmente para modelos de código aberto), poderá aproveitar as bibliotecas de treinamento distribuídas do SageMaker para acelerar e utilizar com eficiência todas as GPUs de uma instância de ML.
Além disso, você também pode considerar a geração de dados totalmente gerenciada, os serviços de anotação de dados e o desenvolvimento de modelos com a técnica de aprendizado reforçado com base em feedback humano usando o Amazon SageMaker Ground Truth Plus.
Um exemplo de arquitetura
Então, qual é a aparência de todos esses componentes ao realizar um caso de uso de IA generativa?
Embora cada startup tenha um caso de uso diferente e abordagens exclusivas para resolver problemas do mundo real, um tema ou ponto de partida comum visto na criação de aplicações de IA generativa é a abordagem de geração aumentada de recuperação.
Depois de conectar todos os serviços da AWS discutidos acima, a arquitetura fica assim:
Pipeline de ingestão — Os dados proprietários ou específicos do domínio são pré-processados como dados de texto. Eles são processados em lote (armazenado no Amazon S3) ou transmitidos (usando o Amazon Kinesis) à medida que são criados ou atualizados por meio do processo de incorporação e armazenado em uma representação vetorial densa. 
Figura 16: Um exemplo de pipeline de ingestão para uma aplicação de IA generativa.
Pipeline de recuperação — Quando um usuário consulta os dados proprietários armazenados na representação de vetores, ele recupera os documentos relacionados usando K-vizinhos mais próximos (kNN) ou pesquisa semântica. Em seguida, ele é decodificado novamente em texto não criptografado. A saída serve como um contexto rico e denso para o prompt. 
Figura 17: Um exemplo de pipeline de recuperação para uma aplicação de IA generativa.
Pipeline de geração de resumo — O contexto é adicionado ao prompt com a consulta original do usuário para obter uma visão ou um resumo do documento recuperado. 
Figura 18: Um exemplo de pipeline de geração de resumos para uma aplicação de IA generativa.
Todas essas camadas podem ser criadas com algumas linhas de código usando ferramentas de desenvolvedor como o LangChain.
Conclusão
Ao longo desse texto, estivemos discutindo a criação de aplicações de GenAI de ponta a ponta usando os serviços da AWS. Os serviços da AWS que você selecionar variam de acordo com o caso de uso ou a abordagem de personalização adotada.
Comece sua jornada de IA generativa com a DNX Brasil e a AWS!
Siga nosso LinkedIn e Instagram para acompanhar lançamentos e novidades.
Para entender como a GenAI pode evoluir especificamente seus negócios, fale com um especialista da DNX Brasil!
Este artigo foi adaptado a partir de AWS Startups.
Artigos relacionados

18
jul





01
jul


27
jun


19
jun


07
jun
